
The truth is that no application will maintain perfect performance in its lifetime. We all know application performance can be influenced by a number of environmental variables and by other applications behavior. Optimizing performance is something that should (but not always does) happen during the development cycle but needs to continue throughout the lifetime of the application.
The reality is troubleshooting Hadoop application performance is complex and extremely time-consuming to do in both Hadoop and Spark.
This is because the information you need to effectively troubleshoot Hadoop application performance is scattered in multiple and disconnected systems. Think about the amount of time you’ve spent sifting through resource manager and log files trying to find out if you have a problem with the application code or if there is a resource contention issue. Finding these needles in the haystack can be done, but there is no getting around how much time it can eat up.
Unfortunately, the current method is complex for a reason because there is no consistency in methodology across frameworks and compute fabrics, i.e. MapReduce, Hive, Spark, Pig, etc. You may have some troubleshoot and monitoring capabilities in one framework but they do not translate to another. Since most data workflows/pipelines use multiple technologies, this makes troubleshooting Hadoop application performance for the entire workflow almost impossible. To simplify Hadoop troubleshooting, you need to change where and what you monitor. Meaning, in addition to monitoring the cluster, you need to be able to monitor the applications running on the cluster. By moving up a level from jobs/tasks to applications, you gain a number of key capabilities necessary to manage a production environment, at scale:
-
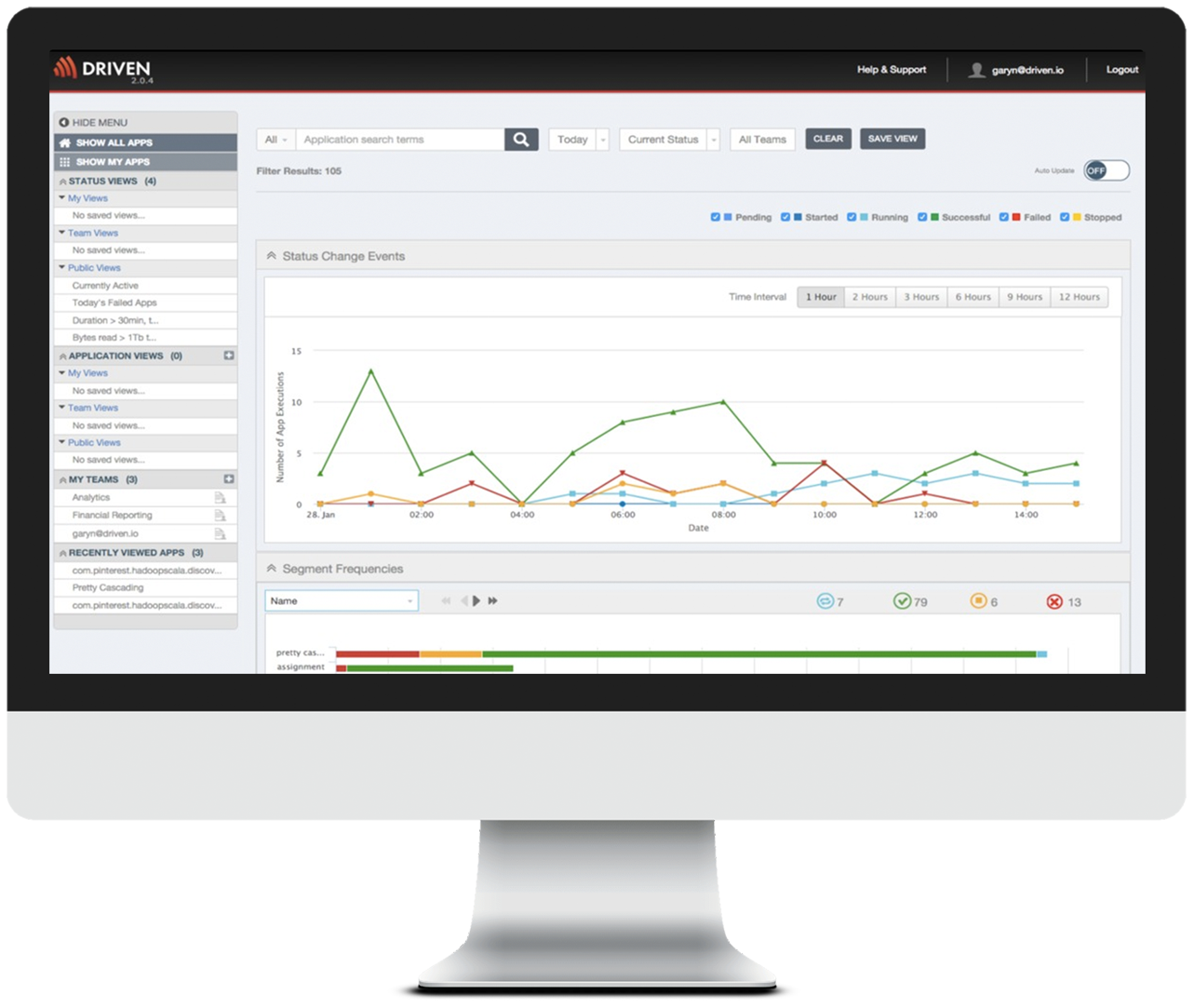
The ability to visualize the status of your entire environment
You must be able to see the status of all your production applications in a single view so you can quickly understand what is running, what has failed, who is consuming what resources and how your environment is performing overall.
-
The ability to visualize how an application actually performs at run-time
Building Big Data applications is complex because you have to deal with multiple technologies, data sources, joins, filters, reads/writes, oh my! You need to be able to visualize the application end-to-end to ensure it is behaving as you expected and not doing something that may impact performance. During development, this visualization is critical to debugging your application and troubleshooting Hadoop application performance. The last thing anyone wants is a new application being deployed that crashed the cluster when it scales up.
-
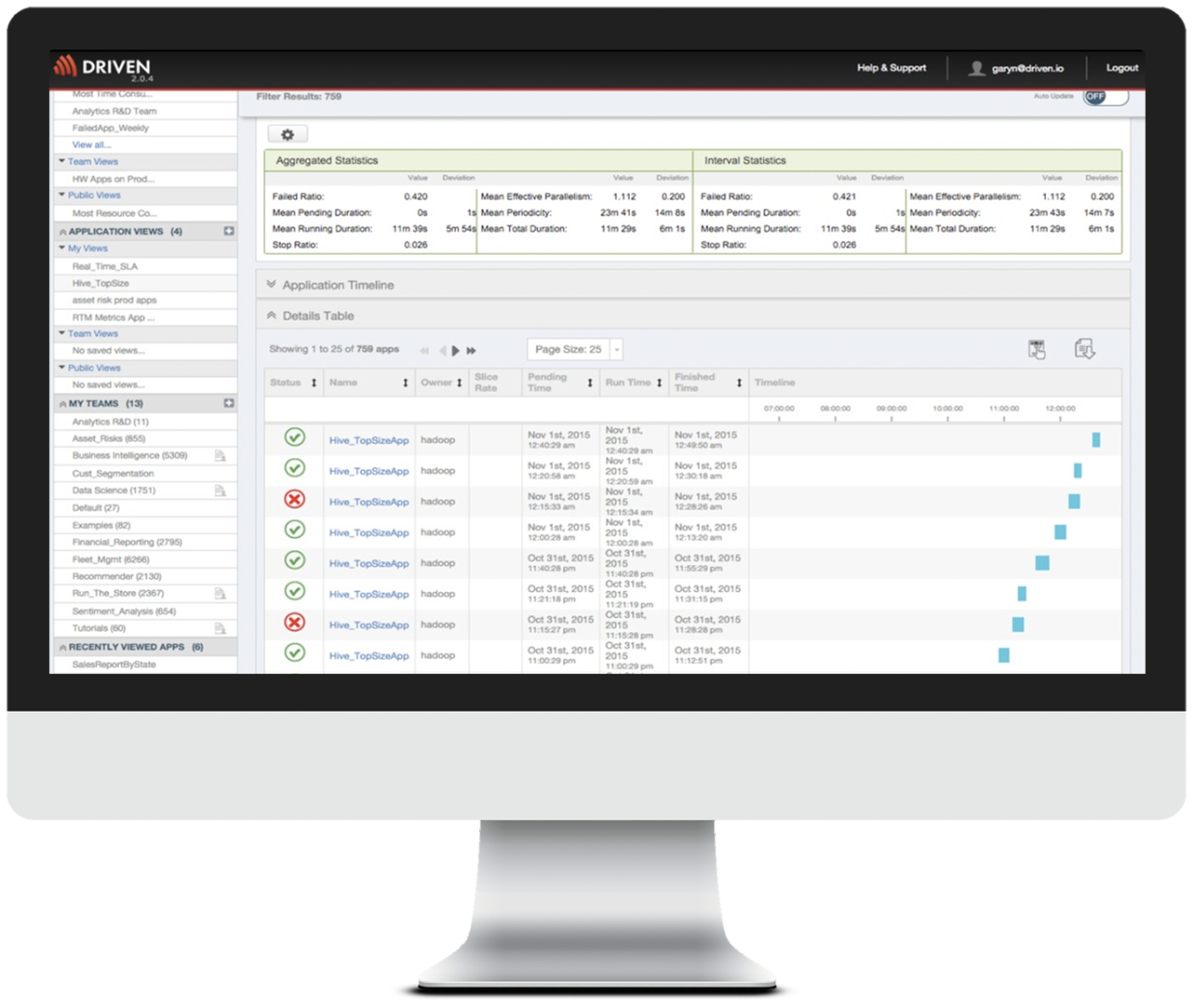
The ability to compare present and past performance
Visualizing the performance of a single run is useful for debugging an application but for performance management, you need to be able to see performance trends to understand if you are at risk for hitting your service levels thresholds. Being able to see historic performance also enables you to understand when a performance degradation began and what happened at that time. For example, was a new version of the application published or did another team deploy an application that is consuming too many resources or did the size of the dataset change.
-
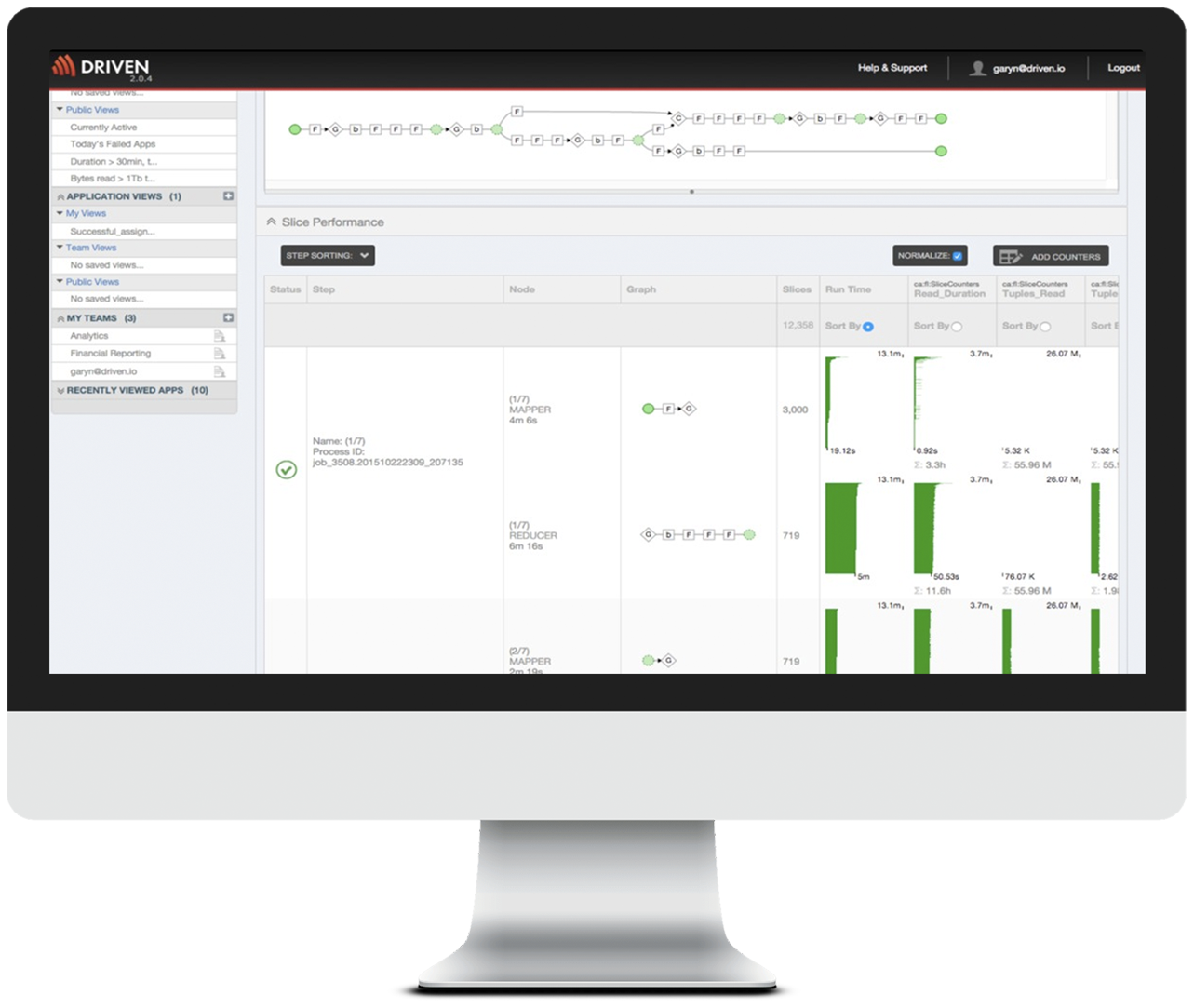
The ability to visualize how each step/job/task is performing and the resources consumed
To get to the next level down for finding the root cause of a performance issue or failure, you need to be able to see the performance statistics at each step and quickly identify the step that has failed. Additionally, in the case of a failure, you need to be able to determine the dependent steps that will not be executed.
-
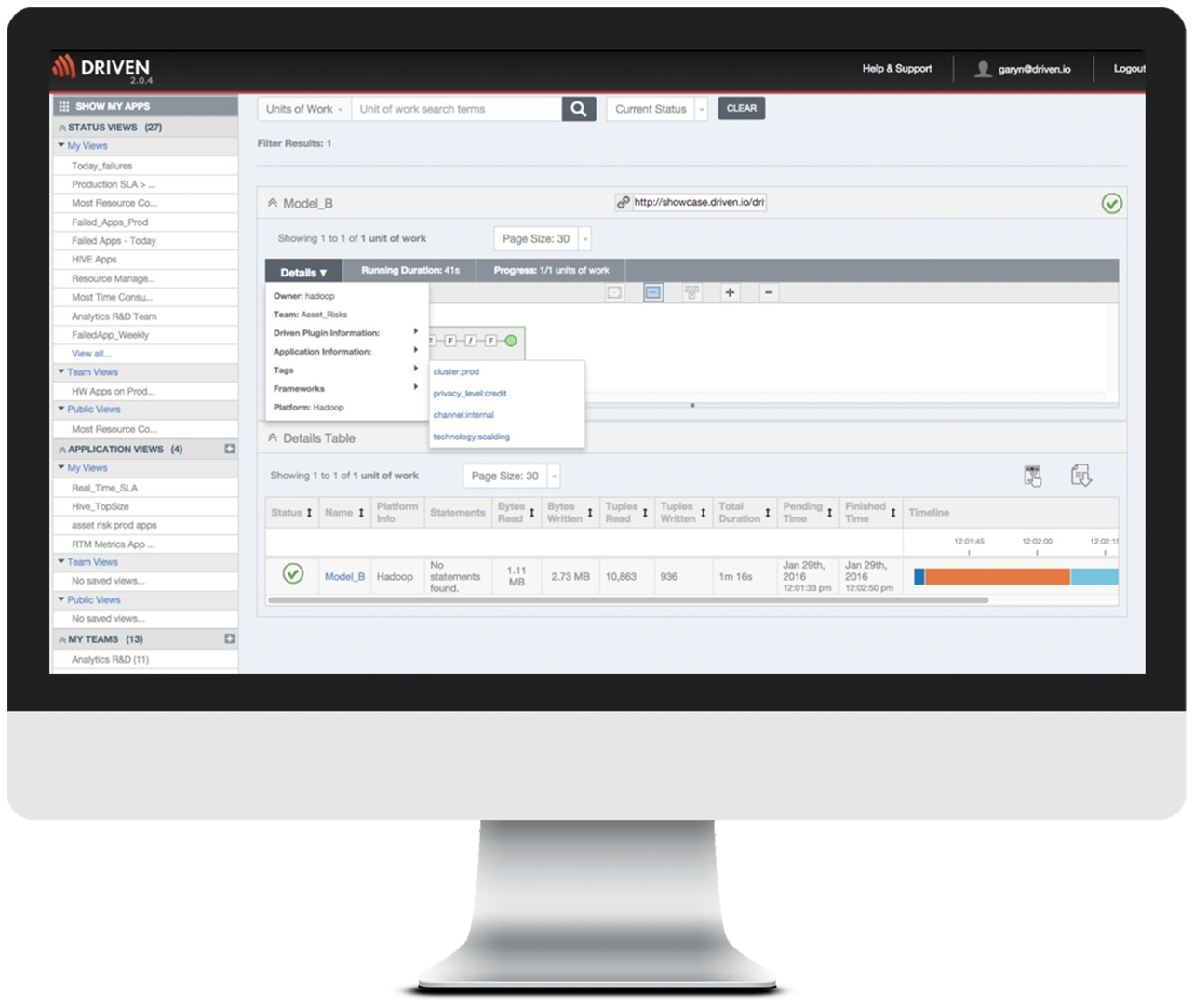
The ability to associate vital operational metadata to an application execution
To be able to operate your production environment and meet business service levels, you need to be able to connect business context to your application executions. For example, when something has happened understanding who is responsible for the application, i.e. the team and the owner, and knowing the priority of the application so you know the business criticality and can make prioritization decisions quickly. Additionally, knowing the upstream and downstream dependencies of the application so you know what other applications are impacted. This is especially critical if the failed application prepares data for several downstream analytics processes. Failures like this can quickly escalate into multiple services level violations and missing datasets. By connecting performance monitoring to business context, you can quickly get ahead of these issues, potentially, before they impact the business and your reputation.

An “Easy Button” for Hadoop Troubleshooting and Application Performance
The screenshots above are all from Driven APM which is a performance management solution specifically designed to monitor and manage Big Data applications. Unlike platform specific tools, Driven manages and monitors all of your Big Data applications, including MapReduce, Hive, Cascading, Scalding, Spark, and Pig, in one solution. Let us help you can take the guesswork (and hard work) out of troubleshooting, managing and monitoring your Big Data applications starting today. Sign up for a free trial of Driven APM.
About the Author: Kim is VP of Marketing at Driven, Inc., providers of Big Data technology solutions, Cascading and Driven. Cascading is an open source data processing development platform with over 500,000 downloads per month. Driven is an application performance management solution to monitor, troubleshoot and manage all your Big Data applications in one place.
SHARE: