We are very happy to see that today the Apache Flink community reached an important milestone in the life of their project: The 1.0 release.
Apache Flink reaching 1.0 was a long and complicated process, so a considerable achievement, especially for a project that aims to cover all aspects of data processing: Streaming, Batch, SQL, Graph-Processing and Machine-Learning.
Choosing a “streaming-first” approach for the architecture and modelling batch-processing as a special case on top of that is a new approach. We are eager to see how this model plays out as more and more people try Apache Flink.
Users of Cascading can immediately leverage all the hard work dataArtisans has contributed the community by creating an integration to allow Cascading applications to run on Flink with virtually no code changes. This shows that Cascading delivers on the promise of being able to move existing applications onto new computational platforms with virtually no code change. It also shows that dataArtisans as a major contributor of Apache Flink are determined to support existing real-world production workloads.
Be aware the support for Cascading on Flink is still not considered ready for production, but as you see in this app it works.
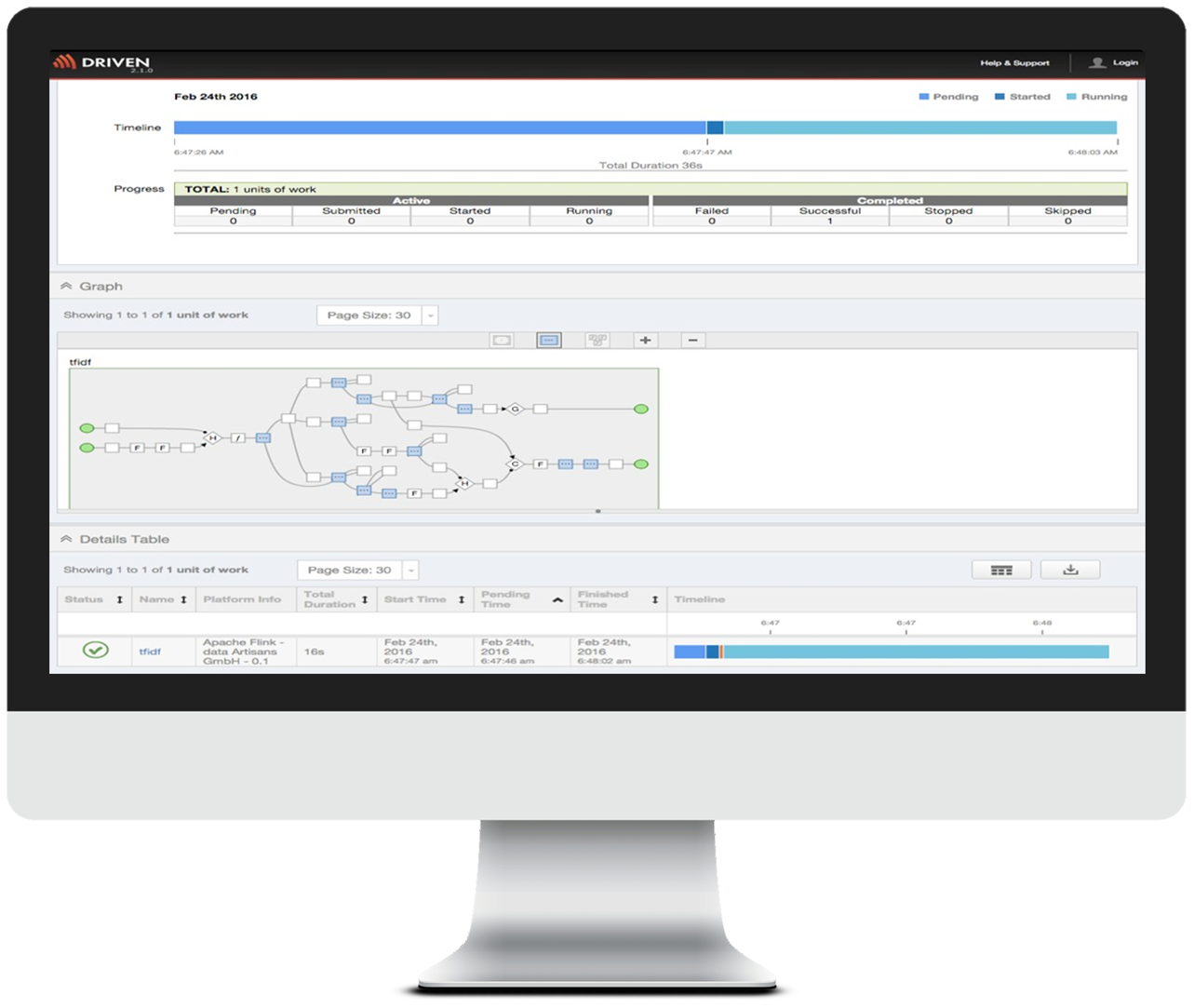
Congratulations to the Apache Flink community. We look forward to a Flink future of data
processing. To learn more visit: http://www.cascading.org/cascading-flink/ to see documentation and access source code.
Additional resources:
- Apache Flink 1.0 announcement: http://flink.apache.org/news/2016/03/08/release-1.0.0.html
- dataArtisans blog: http://data-artisans.com/flink-1.0.0/