
In our last post, we talked about the possible options for organizing to achieve operational excellence on Hadoop and the pro’s and con’s of each model. A couple of key points that surfaced during our conversations with our customers who have successful production deployments were: 1) be conscious of the fact that data applications are rarely developed and managed in a vacuum so setting up a collaborate environment is important, and 2) there is an inverse relationship between scale and performance visibility. Meaning, the more you scale, the less visibility you have to what is happening in your environment.
In this post, we will dive deeper into why fostering a collaborative environment and application performance visibility are key factors to achieving Hadoop production readiness and operational excellence with your Big Data applications.
Before you ask… yes, there are a number of excellent cluster management and monitoring solutions and you absolutely need them. They focus on performance metrics for the cluster i.e. CPU utilization, I/O, disk performance, disk health, etc. However, when it comes to your applications, these solutions simply do not capture the metrics to provide application-level performance monitoring. This why most operations teams are forced to wade through Resource Manager, log files and thousands of lines of code to troubleshoot a performance problem. Needless to say, this can take hours and, at scale, is not sustainable.
To mitigate reliability and performance risks as you scale, you need to think about application performance monitoring as well as cluster performance monitoring. So what does that mean? These are the common challenges you will face as you scale that will make it difficult to maintain operational excellence:
- We can’t maintain reliable, predictable performance for scheduled jobs/queries. If there is a slowdown, it takes too long to troubleshoot the issue and we cannot easily find the root cause
- We don’t know what teams are consuming what resources and if they are being consumed efficiently, especially related to ad-hoc Hive queries
- We are not sure what service levels we can commit to for business critical applications
- We don’t know which jobs/queries/applications are business critical when there is a slowdown, who owns them or the downstream impacts
- We have policies and best practices in place but its difficult to enforce them across the organization
To address these challenges, we’ve compiled this list of 7 things to do to ensure your Hadoop production implementation is sustainable and meets business expectations:
Create a collaborative environment across development, QA, and operations teams covering the lifecycle of the application. This includes technology, people, and process.
- Collaboration should start at the development phase with your development, data analysts and operations teams working together to build better data applications that are optimized and resilient
- When things go wrong, enable notifications to quickly assemble a cross-functional team to troubleshoot the application, identify the root cause and quickly fix the issue.
- In both cases, leverage technology to allow your team members access to the same application performance data at the same time. This should also include access to historical runs so present and past performance can be compared.
Segment your environment by assigning applications to teams and associating other business relevant metadata such as business priority, data security level, cluster, technology, platform, etc.

- To understand what is happening, where and by whom, the environment needs to be organized and segmented in ways that are meaningful and aligned to how your business operates.
- Associating applications to teams, departments or business units allow your operations teams to create the necessary cross-functional support organization to troubleshoot issues.
- Segmentation also makes reporting more robust as you can create chargebacks, audit and/or usage reports by multiple dimensions. This makes managing the business of Big Data easier and provides evidence of ROI for senior leadership.
Provide operations teams with a single view of all the applications running in the environment
- Bouncing between multiple monitoring tools to track down issues is not sustainable for operations teams managing potentially dozens of technologies. A single view of the status of all the applications, regardless of cluster, technology or framework is essential to enabling these teams to support the enterprise effectively.
Give cross-functional teams the ability to visualize an entire data pipeline vs. just a single step/job/task.
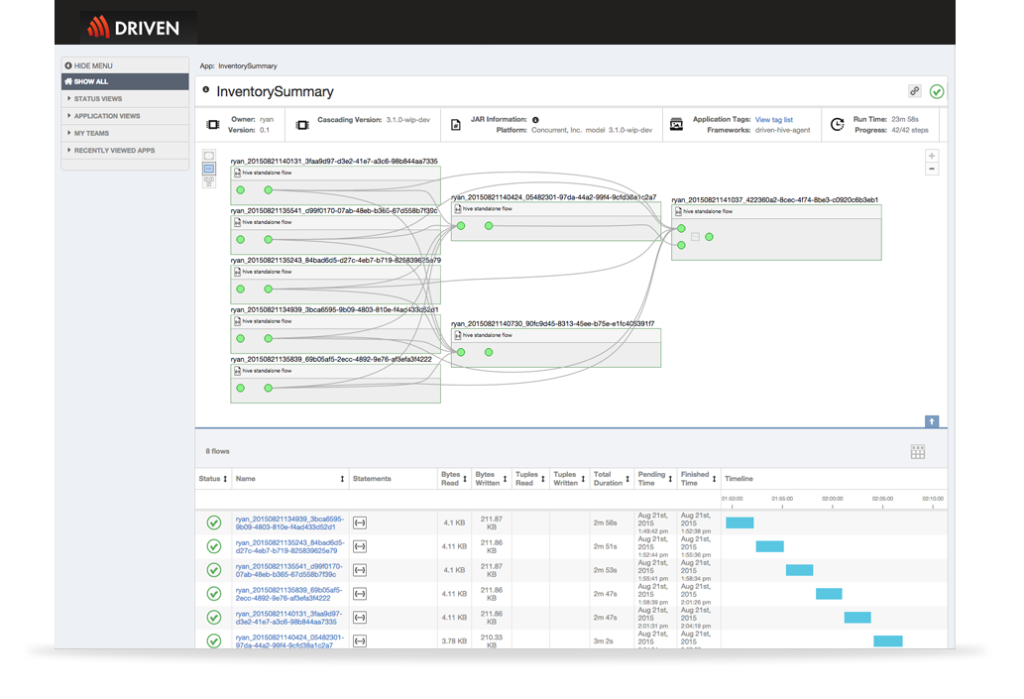
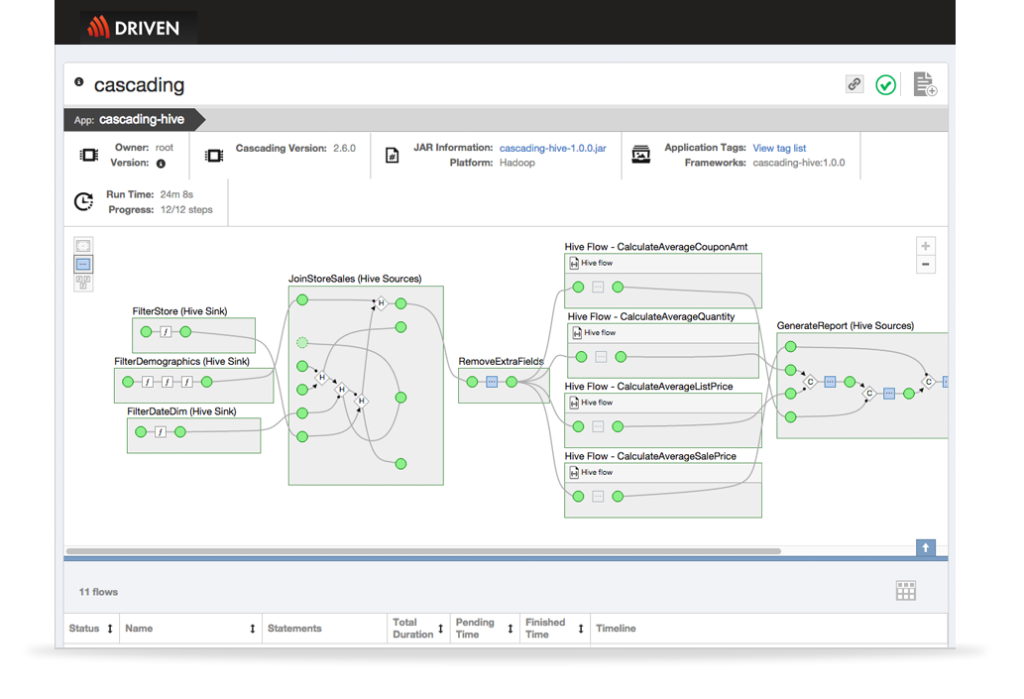
- Some cluster monitoring tools provide some basic information about how a job/task performed but only about that job/task and only for that moment of time. By enabling your development and operations teams to visualize the entire data pipeline/data flow, two things happen: 1) everyone can validate the application is behaving as intended; and 2) teams understand the inter-app dependencies and the technologies used in the application.
- This is also a great way to enable the operations teams to advise data analysts or data scientists on best practices and make their applications or queries more efficient, saving everyone headaches in the long-term.
Surface real-time and historic application performance status with the ability to drill down into performance details such as slice rate, bytes read/written, wait time, processing time, etc.
- Visualizing application performance metrics will help your teams quickly troubleshoot if the application is not efficient, if recent changes impacted performance or if there are resource constraints on the cluster. This alone can save you hours of combing through log files and provides the data you need to tune the application right the first time. This is a key tactic to achieving operational excellence.
- Performance monitoring details should surface the application metadata tags business context can be applied to any issue. For example, identify what team owns the application/query, the business priority class, etc. This information can be invaluable when a business critical scheduled job is being starved of resources because a large ad-hoc query is submitted during run-time.
- In a shared resource environment, more business teams ask for service levels so they can be sure their data is available when they need it. For team to confidently commit to service levels, you need to chart historic performance trends so you can determine what service levels are achievable based on actual data not on wishful thinking.
Track data lineage to support compliance and audit requirements.
- This step is often overlooked as a backend reporting problem but the reality is you need to capture this data from the start. It can be an arduous and time-consuming process to retrospectively string together logs to track sources, transformations and ultimate destination of data. Your team has better things to do with their time. To simplify the reporting process, enable the compliance teams to visualize the entire data pipeline/data flow so they can see, in one view, sources transformations, joins, and final output location of the entire application.
Enable alerting and notifications for the various teams
- When anomalies are detected, you want to notify all the relevant team members so cross-functional troubleshooting and impact analysis can start immediately.
- Utilize existing notification systems and processes so you are not creating a separate support process for these applications
We have found that organizations that implement these best practices for application performance monitoring are up to 40% more efficient in both managing application development and production environments. Implementing these tactics will help you ensure you can sustain Hadoop operational excellence and meet business needs, but it takes technology, people and process to get there.
To learn more, download our free whitepaper: 9 Best Practices to Achieve Operational Readiness on Hadoop
About the Author: Kim is Sr. Director of Product Marketing at Driven, Inc., providers of Big Data technology solutions, Cascading and Driven. Cascading is an open source data processing development platform with over 500,000 downloads per month. Driven is an application performance management solution to monitor, troubleshoot and manage all your Big Data applications in one place.
Take Driven for a test drive with our free 30-day trial.
SHARE: