Apache Spark Performance Monitoring Solutions From DRIVEN
Consolidate Apache Spark Performance Monitoring for all models, batch, machine learning or streaming, in one solution
Apache Spark applications bring a new set of operational challenges especially when the Hadoop resources are shared across multiple data processing teams. Because everything runs in-memory and memory is a finite resource, it quickly becomes complex juggling act to manage resources so these applications run optimally. Meaning, there is not an excessive amount of swapping or spilling to disk. When adding new jobs, operations teams must balance available resources with business priorities. This delicate balance can quickly be disrupted by new machine learning or streaming jobs being introduced that consume more resources than available. DRIVEN provides performance monitoring for Apache Spark so you can understand who is running what and how often and key performance statistics to determine if the application is within policies.
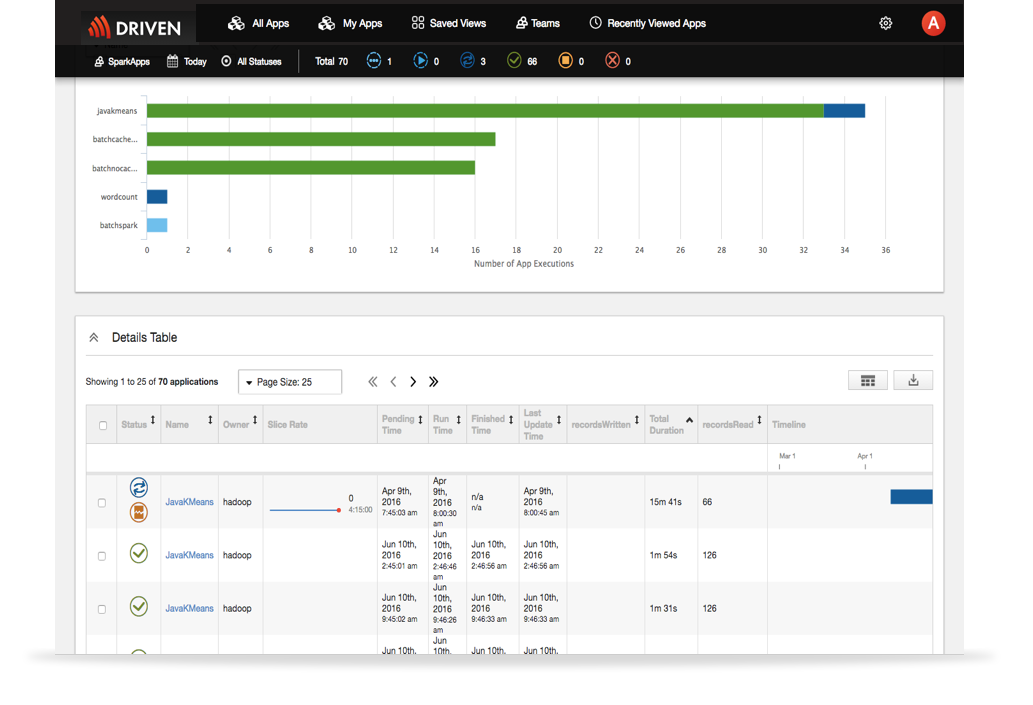
Real-Time Operational Visibility into Spark Applications
- Gain insights into your test, pre-production or production Spark applications
- Powerful search to search on almost anything, such as Spark app name, RDD unit of work, table names, etc. and it’s simple and fast
- A built-in, scalable metadata repository enables you to analyze current application performance and execution behavior compared to historic performance
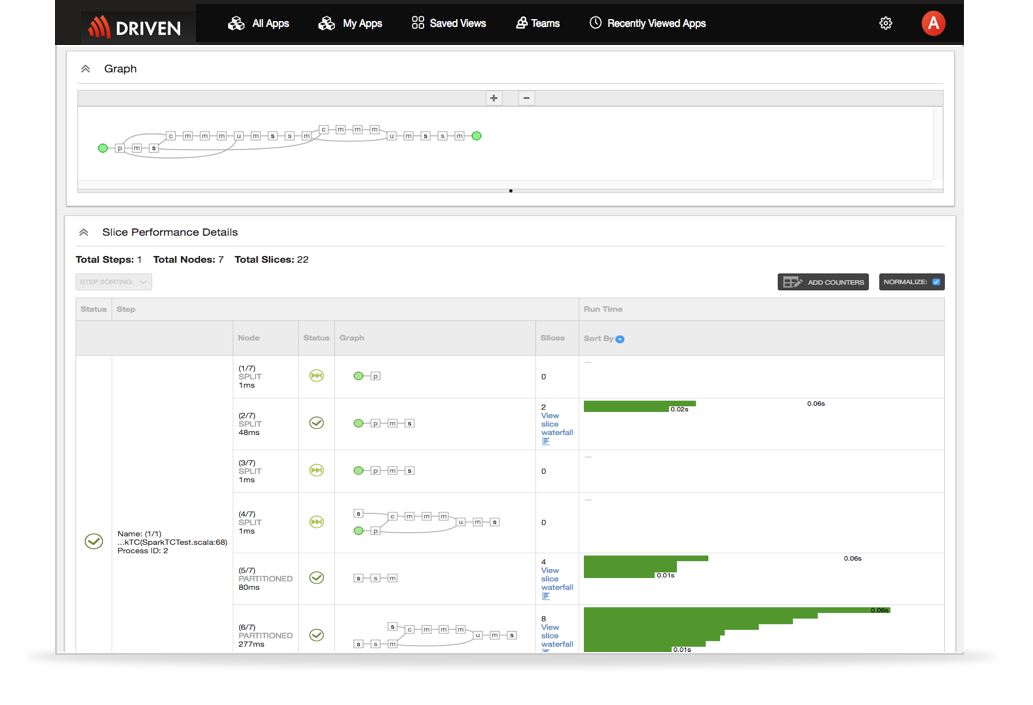
Monitoring for Spark Applications and Debugging
- See how efficient your applications is at runtime by seeing skipped vs. executed steps
- Real-time monitoring of Spark application execution with workflow visualization
- Rich performance metrics including all the Spark counters and custom counters for each of your Spark executions provides deep insights into potential performance optimizations.
- Quickly identify where there are resource constraints and application bottlenecks
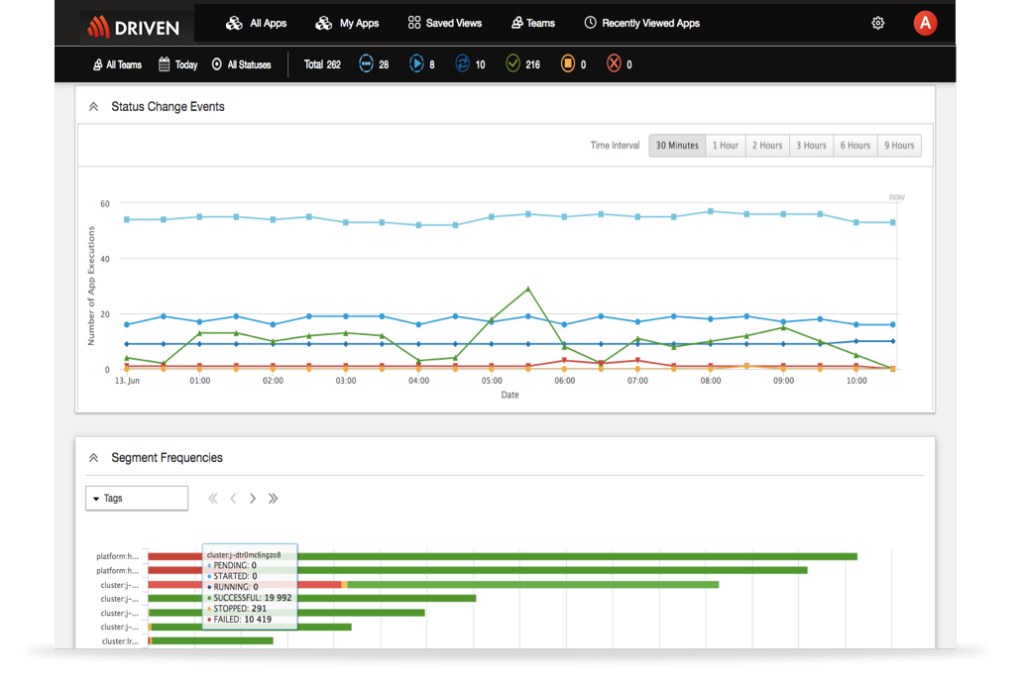
Manage The Business Of Apache Spark Big Data Operations
- Integrate DRIVEN alerts and notification into your support/ticketing systems and leverage existing processes
- Filter on operational criteria to allow administrators to easily manage and enforce policies.
- Organize and segment your Spark applications based on any user defined metadata, such as a team, division, organization, or application name.
- Improve general resource management as well as reporting for chargebacks