FOR IMMEDIATE RELEASE
New Release from Driven, Inc. Delivers End-to-End Monitoring and Management for Hadoop and Spark Applications Running in Any Environment, Anywhere
SAN FRANCISCO – Jun. 21, 2016 – Driven Inc., formerly Concurrent, Inc., the leader in Big Data application performance monitoring (APM), today announced the next version of Driven. Driven 2.2 delivers to customers the ability to monitor and manage multi-tenant heterogeneous Hadoop and Spark environments, that are deployed anywhere, within a single solution.
Driven Cloud, a component of the Driven 2.2 software, is the first SaaS offering for Big Data application monitoring. Driven Cloud monitors and manages applications running on Hadoop as a service, Hadoop or Spark on premise or both. It is designed to serve the needs of organizations that need the power of Driven to quickly troubleshoot, optimize and monitor their Hadoop data processes and the simplicity and low setup costs of a cloud solution.
The Big Data landscape is getting more complex, with new open source projects and products being announced almost weekly. With little industry standardization, DevOps teams are faced with managing and monitoring multiple technologies as organizations implement the technologies best suited to solve specific business problems.
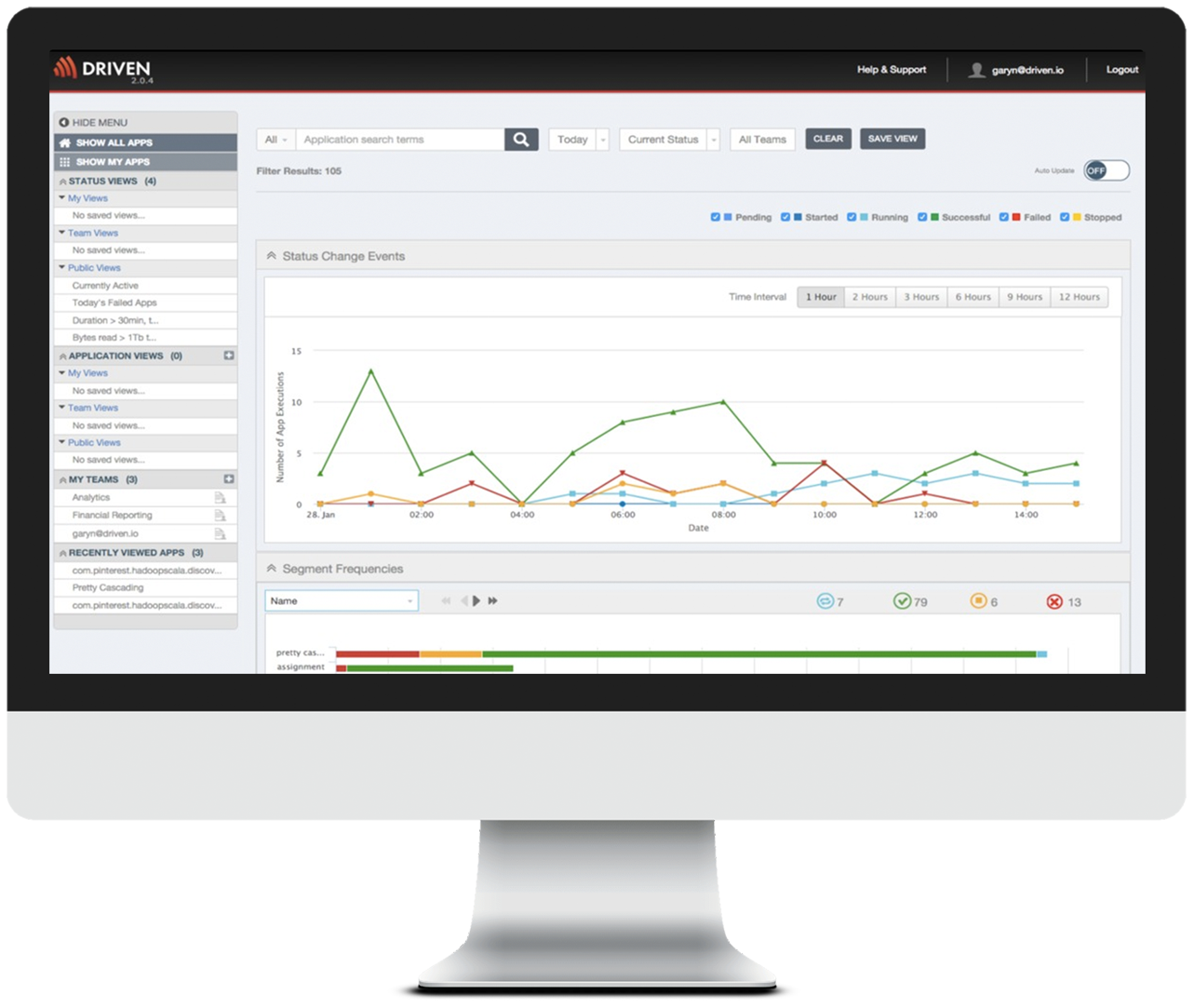
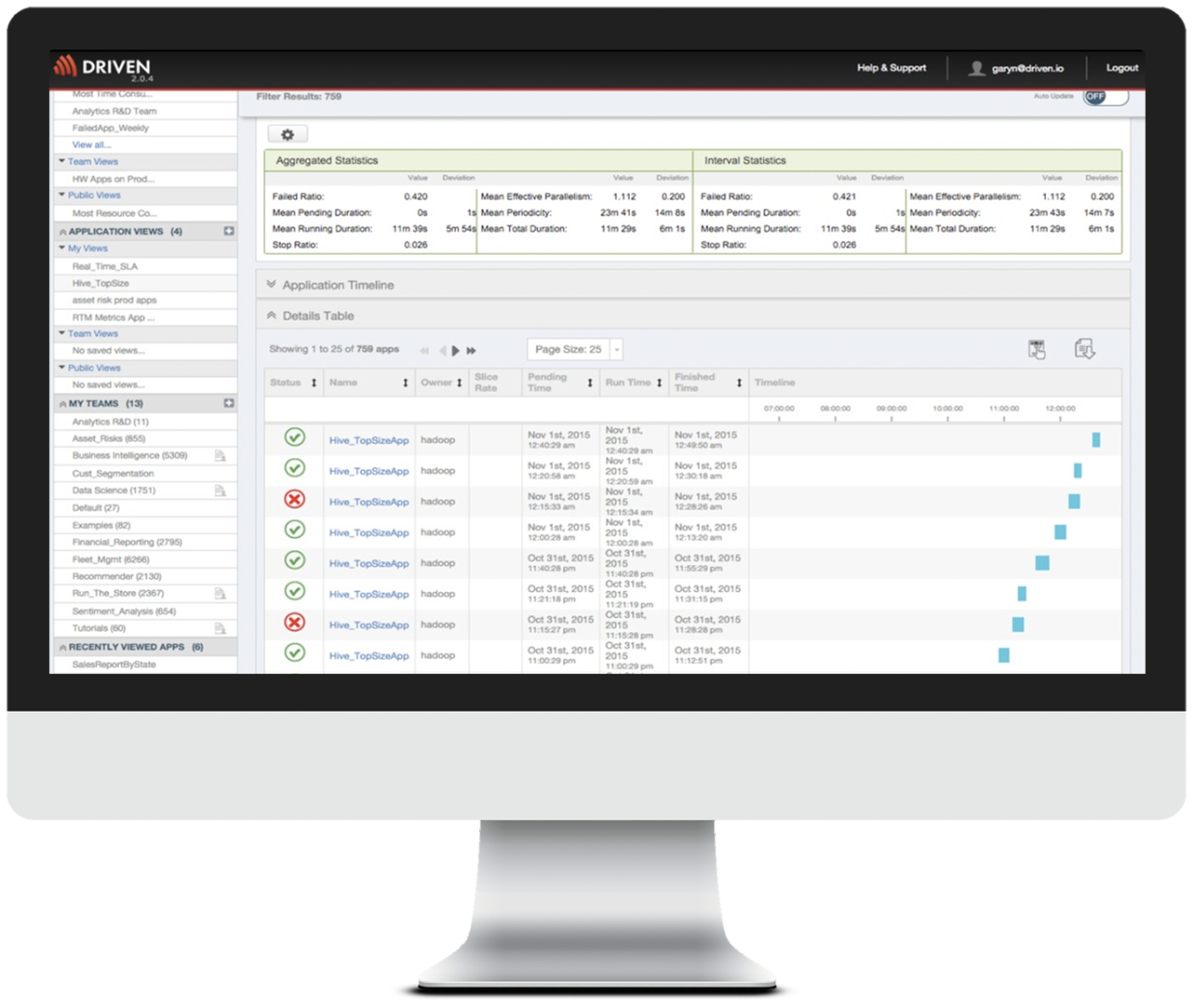
Driven 2.2 helps DevOps teams gain control over the increasing chaos of large scale Hadoop and Spark implementations by enabling high fidelity monitoring of Apache Hive, MapReduce, Cascading, Scalding, Apache Spark applications and related Big Data technologies. No other single solution on the market delivers this level of coverage to empower teams with continuous visibility and traceability from start to finish.
Key features of Driven 2.2 include:
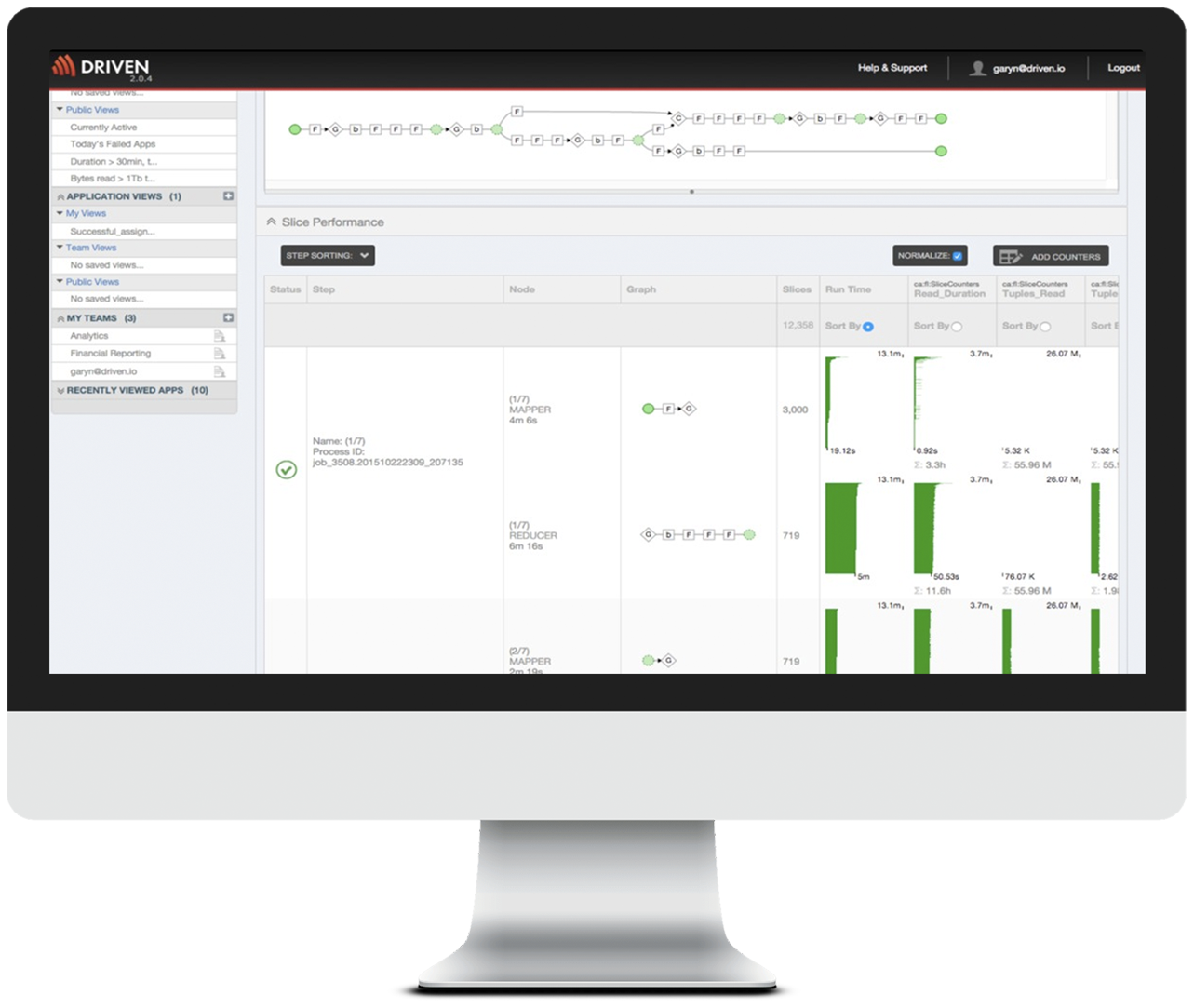
General Availability of Apache Spark Performance Monitoring: Monitor Spark Core, MLLib, or Spark Streaming applications by visualizing application logic and collecting all the key performance and operational metrics. Enabling developers and data scientists to visualize diagnose and fix their own performance anomalies and operations teams to quickly identify anomalous processes and their owners, allowing greater control of Spark resources on a multi-tenant cluster.
Driven Cloud: Organizations of any size can use Driven to build, monitor and manage their Big Data applications with minimal set up time. Driven Cloud users simply install the agent or plugin to start sending application performance data to the Driven Cloud Service. Driven Cloud supports all the major distributions both on premise (ex. Cloudera, Hortonworks, MapR) and cloud services (ex. Amazon EMR, Microsoft Azure, IBM BlueMix, Qubole, Altiscale).
Additional Enterprise Capabilities:
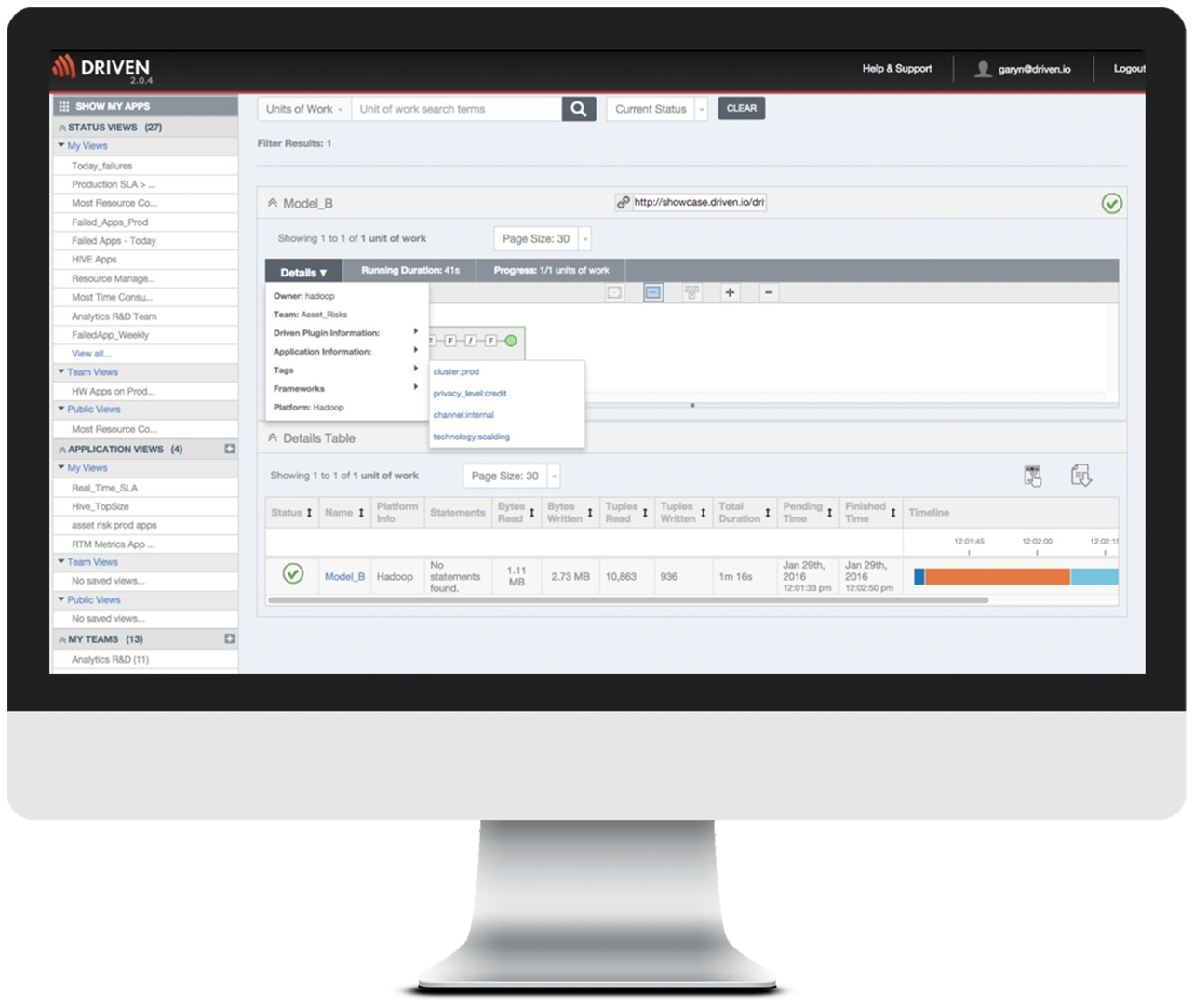
Together with Driven’s ability to bring business, organization, and performance context to each and every data process, DevOps and Administrators can manage user access to Driven with their directory service, thereby segment their own scheduled and ad-hoc transactions without involving the central administrators.
With this convenient secure access, Driven 2.2 is accompanied with a redesigned user interface allowing users to quickly find what they are looking for, analyze historical executions, share their findings with colleagues, and create custom dashboards.
To learn more about Driven and how customers, such as Expedia and LiveIntent, are using Driven to optimize performance and reduce time-to-market, register for our July 20th webinar. In 30-min, we will go through some common ways our customers use Driven and a quick demo so you can see Driven in action.
Driven is available to try for free at http://www.driven.io/choose-trial. For pricing and more information, visit http://www.driven.io/pricing-and-packaging or email us at sales@driven.io.
Supporting Quote
“As organizations scale their use of Hadoop and Spark through their own data centers, through cloud service providers, or inevitably both, its becoming more and more difficult for DevOps teams to understand and react to what is happening or what has happened. The future of data processing is both in the cloud and on premise, and Driven is uniquely positioned to deliver a comprehensive data processing monitoring and management platform for next generation enterprise data.
– Gary Nakamura, CEO, Driven, Inc.
“Driven Cloud was so simple to implement and gives us visibility into the performance of our applications whenever we need it. This helps us ensure our applications are consistently delivering data on-time to the business so they, in turn, can use it to better serve our customers.”
– Eric Raab, EVP, Engineering, LiveIntent
Supporting Resources
• Driven: http://www.driven.io
• Cascading: http://cascading.org
• Company: http://driven.io/
• Contact us: http://driven.io/contact-us
• Twitter: http://twitter.com/drivenio
• LinkedIn: http://www.linkedin.com/company/concurrent-inc-
About Driven, Inc.
Driven, Inc., formerly Concurrent, is the leader in data application infrastructure, delivering products that help enterprises create, deploy, run and manage data applications at scale. The company’s flagship enterprise solution, Driven APM, was designed to accelerate the development and management of enterprise data applications. Driven is the team behind Cascading, the most widely deployed technology for data applications with more than 500,000 user downloads a month. Used by thousands of businesses including eBay, Etsy, The Climate Corp and Twitter, Cascading is the de facto standard in open source application infrastructure technology. Driven is headquartered in San Francisco and online at http://driven.io/.
Media Contact
Kim Loughead
VP, Marketing, Driven, Inc.
(415) 813-1010
kim@driven.io