
For longer than I’d like to admit, I put off learning Hadoop the way I put off making dentist appointments. I had years of experience building data-centric applications and APIs, but with Hadoop there were all these intimidating new questions. Which distribution? What cluster size? MapReduce? How do I test? What do Hive, Pig, Phoenix, Tez, Spark, Storm, Flink, and Yarn do?
Then, my career led me to the big data space, and I jumped in. Happily, as is often the case, my fears were unfounded. Deploying apps on Hadoop — especially these days — turns out to be both easy and affordable. In fact, it’s now possible for a single developer with a single laptop to code, deploy and monitor complex data workflows in just a few hours.
In this tutorial-ish post, I’ll take you through the app that helped me get over my Hadoop fear, in the hopes that it will help you get past yours. You’ll see how easy it can be to spin up a Hadoop cluster, code a data flow, and debug it. All you need is decent Java skills, an AWS account, and a couple of hours.
My Sample App for Conquering Hadoop-phobia
The app we’ll build — the one that helped me move past my Hadoop fear — is a simple one, but it demonstrates a surprising amount of the stuff in a real-world data pipeline. Here’s what it will do:
- Read data from files on AWS S3
- Perform a few ETL operations
- Use the COPY command (parallel insert) to output the results to AWS Redshift
Here is a directed acyclic graph (DAG) showing what the sample app will do:
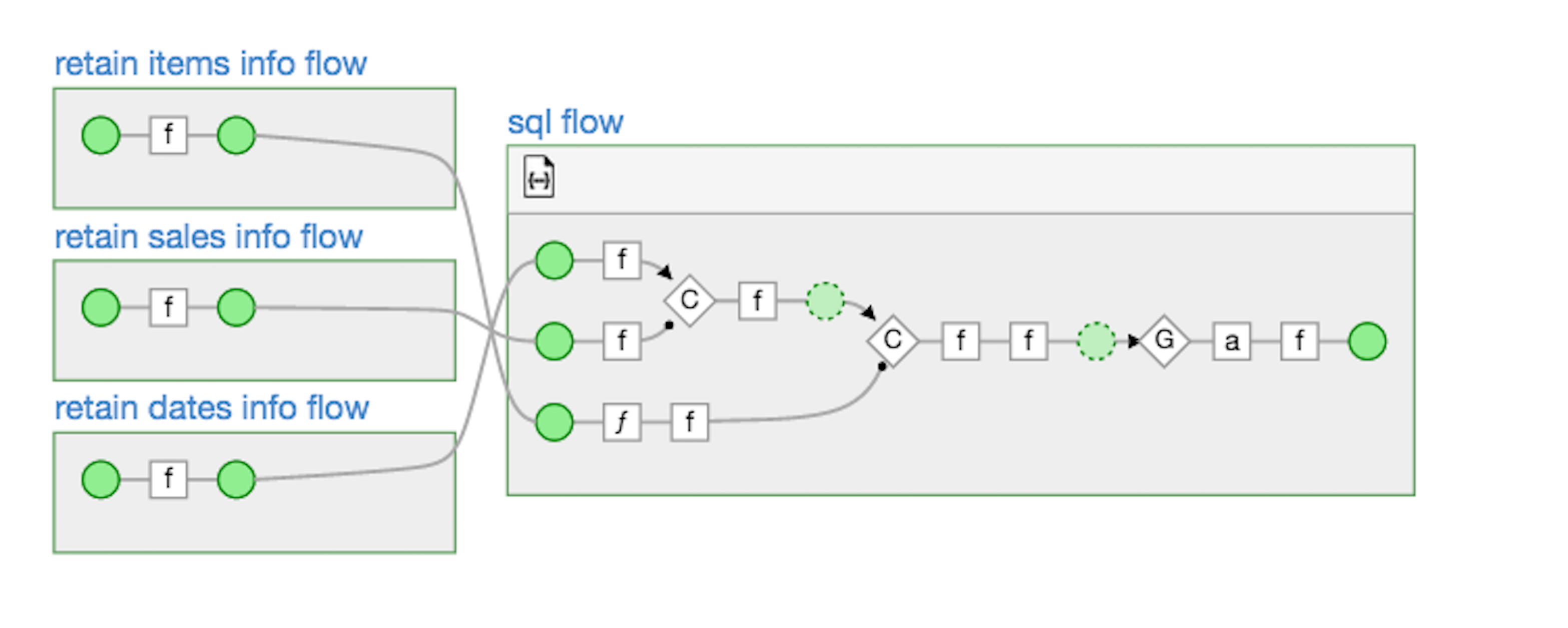
Tackling this app made me confront a whole bunch of different fears around Hadoop, but I found ways of conquering them all. Here’s how I went about it.
Hadoop Fear #1: Spinning Up and Managing a Hadoop Cluster
How I Conquered It: Discovering AWS Elastic MapReduce
Just thinking about launching, configuring and managing a multi-node Hadoop cluster is a great way to ruin your day. I mean, even if the long list of things you have to do to set up your cluster (https://code.google.com/p/distmap/wiki/SetupHadoopLinux) actually works, then you have to babysit the thing day and night. No thanks.
Luckily, I discovered AWS Elastic MapReduce (EMR), which lets you easily spin up a Hadoop cluster of any size. I’m used to wrangling with software installations, data source integrations, firewalls, users, roles, permissions and multiple version conflicts. I’m used to everything being painfully tedious. What I’m not used to is my own maintenance-free, multi-node cluster to play with at my discretion. AWS EMR basically revolutionized my understanding of not only how someone can deploy distributed data applications, but who can deploy them. Meaning anyone, like me. Or you.
All you have to do get going with AWS EMR is install AWS CLI (http://aws.amazon.com/cli/) and execute a command, like this:
aws emr create-cluster \
--ami-version 3.3.1 \
--instance-type $INSTANCE_TYPE \
--instance-count $INSTANCE_COUNT \
--bootstrap-actions Path=$INSTALL_SDK_URL,Name=SDK_LINGUAL_BOOTSTRAP \
--name "cascading-aws-tutorial-2" \
--visible-to-all-users \
--enable-debugging \
--auto-terminate \
--no-termination-protected \
--log-uri s3n://$BUCKET/logs/ \
--steps (omitted for readability)
You can see the whole script here:
https://github.com/Cascading/tutorials/blob/master/cascading-aws/part2/src/scripts/emrExample.sh
Hadoop Fear #2: Coding in MapReduce
How I Conquered It: Realizing I Didn’t Have to Code in MapReduce
MapReduce is a beast. It forces you to think about details that most people shouldn’t have to think about. It’s like, instead of just buying a ticket from New York to San Francisco, you have to fly the plane.
But these days you really don’t have to interact directly with MapReduce. In my case, I coded to Cascading, an open-source framework that sits on top of MapReduce. (I work for the company that manages Cascading, but there are other app frameworks out there too.) The great thing about Cascading is that you can just document the data flows you want, and it takes care of the details.
For example, here’s how you can iterate over tuples in a stream and perform an operation on each “time” field:
processPipe = new Each( processPipe, new Fields( "time" ), new DayForTimestamp(), Fields.ALL );
And here’s how you could then group on the “day” field.
processPipe = new GroupBy( processPipe, new Fields( "day" ) );
Cascading allows you to program workflows the same way you think about them. Using pipes, filters, functions, joins and so forth.
You can view the Cascading application I wrote here, https://github.com/Cascading/tutorials/blob/master/cascading-aws/part2/src/main/java/cascading/aws/SampleFlow.java.
Hadoop Fear #3: Data Source Integrations
How I Conquered It: Taking advantage of easily configurable taps
This was actually a biggie, again because I had all these questions. How could I output my dataflow results to the data store of my choice? Did I have to write custom integrations for each? Did I need to use another application just to get my data into HDFS?
Cascading ships with around 30 “taps” — modules that make it really easy to exchange data between popular platforms. My S3 tap and Redshift tap each consist of one line of code:
S3:
Tap itemsDataTap = new Hfs( new TextDelimited( ITEM_FIELDS, "|", ITEM_FIELDS_TYPES ), itemStr );
Redshift:
Tap resultsTap = new RedshiftTap( redshiftJdbcUrl, redshiftUsername, redshiftPassword, "s3://" + s3ResultsDir + "/part2-tmp", awsCredentials, resultsTapDesc, new RedshiftScheme( resultsFields, resultsTapDesc ), SinkMode.REPLACE, true, true );
For a full list of Cascading taps, check out: http://www.cascading.org/extensions/
Hadoop Fear #4: Debugging and Monitoring
How I Conquered It: Getting Driven
Debugging can rise to a whole new level of pain in Hadoop. Instead of just looking for compilation errors, you’ve got to track down what happened in your cluster, which can be different each time the app runs. That can take hours when all you have are Hadoop’s built-in JobTracker, the Job History Server, and a sea of Hadoop log files.
Thankfully, there are now better tools for visualizing what your apps and your clusters are doing. The one for Cascading is called Driven, and it can make your life a lot easier. Basically, it gives you really good visibility into how your application behaves.
You can drill down into any point of this DAG (directed acyclic graph) to see exactly where data is being read from or written to, as well as exactly what functions are operating on which fields. As you scale up, it records every run of every application on your clusters. That gets you historical visibility over time. With Driven, you can visually inspect each element (down to the field level) of your application, and immediately surface the stack trace of any error:

As you can imagine, Driven makes debugging in Hadoop a lot easier. You can get start using Driven for free here: http://driven.io
Hadoop Fear #5: Cost
How I Conquered It: Starting Small and Scaling Up
Spinning up Hadoop clusters, even on AWS EMR, can get expensive. If there isn’t an immediate business need and a budget behind it, you’re never going to secure the budget for a full-on Hadoop cluster.
Luckily, there are ways to start out small and grow from there. In my case, I spun up just a single-node EMR cluster, and then automatically terminated it after each run. When spinning up the EMR cluster from the CLI, you specify how many nodes you want (–instance-count) and that you want it to terminate automatically (–auto-terminate).
This allows you to get your feet wet while paying only for exactly the resources you need for the time you need them. Once you’re ready, you can scale up.
Putting it all together
I documented all the steps I took and wrapped it into a tutorial that you can view here, http://docs.cascading.org/tutorials/cascading-aws/.
Hopefully you’ll reach to the same conclusion I did: Hadoop’s not so scary after all.
* * *
Ready to give it a shot? Instantly view your Hadoop Apps Online with Driven. Try it for Free Now!
About Ryan Desmond
 Ryan is a Solution Architect for Concurrent Inc, the company behind Cascading and Driven. Cascading is among the most widely used and deployed technologies for Big Data applications with more than 400,000+ user downloads a month. Driven is the industry’s first application performance management solution for managing and monitoring all your Big Data applications in one place. Driven provides detailed performance insights for Cascading, Apache Hive, MapReduce and Apache Spark data processing applications.
Ryan is a Solution Architect for Concurrent Inc, the company behind Cascading and Driven. Cascading is among the most widely used and deployed technologies for Big Data applications with more than 400,000+ user downloads a month. Driven is the industry’s first application performance management solution for managing and monitoring all your Big Data applications in one place. Driven provides detailed performance insights for Cascading, Apache Hive, MapReduce and Apache Spark data processing applications.