
When an enterprise Hadoop app fails to perform up to expectations, the finger-pointing can get ugly. Developers blame the operators, convinced that adding hardware, inspecting the data, or improving cluster utilization is the answer. Operators, in turn, throw the problem back on developers, arguing that code optimization is what’s needed. Even in forward-thinking teams with a collaborative DevOps culture — where the two sides work together to solve problems — there’s always a tension between adding compute resources and tweaking the code.
Who’s right? It depends, of course. It’s critical, therefore, that developers and ops teams get the insights they need to collaborate on resolving Hadoop bottlenecks. For example, how much of a performance gain would result from each additional node? Have developers written their code in a way that Hadoop can parallelize complex tasks? What other factors might be affecting performance?
In this post, I’ll present a high-level overview of how Driven helps to answer these questions, giving developers and operators the data they need to model and validate assumptions about application performance on Hadoop. (You can get Driven here: http://www.driven.io .)
A Sample App for Optimizing Performance
To show how Driven can help teams collaborate on resolving Hadoop performance problems, we’ll go through a high-level exploration of an application that produces a sales report broken out by region, date, and time. For instructional purposes, we’ll minimize up-front code optimizations and start with a small test data set. We’ll run our application on an AWS Elastic MapReduce cluster.
Off the bat, Driven shows us a directed acyclic graph (DAG) of our application’s components, confirming that the data flow is what we want it to be:
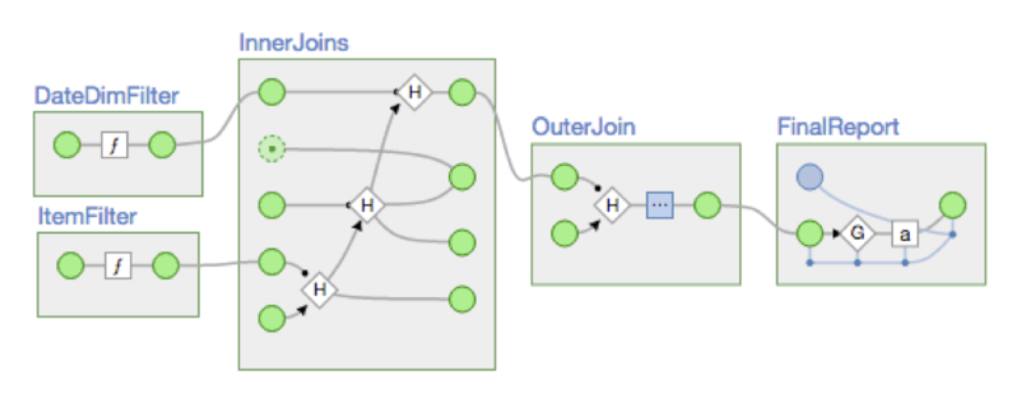
As we intended, the upfront processing steps — ItemFilter and DateDimFilter — can run in parallel, since they don’t share input sources. The app’s other components — InnerJoins, OuterJoin and FinalReport — need to run serially since each depends on the output of another step. Now let’s look at how the individual steps perform.
Add Nodes or Call in the Developers?
To see how additional nodes boost performance, we can run the application on Elastic MapReduce on progressively larger clusters, using Driven to grab execution durations for each application component. With this data, we can produce the graph below, which shows execution time by component as cluster size grows:
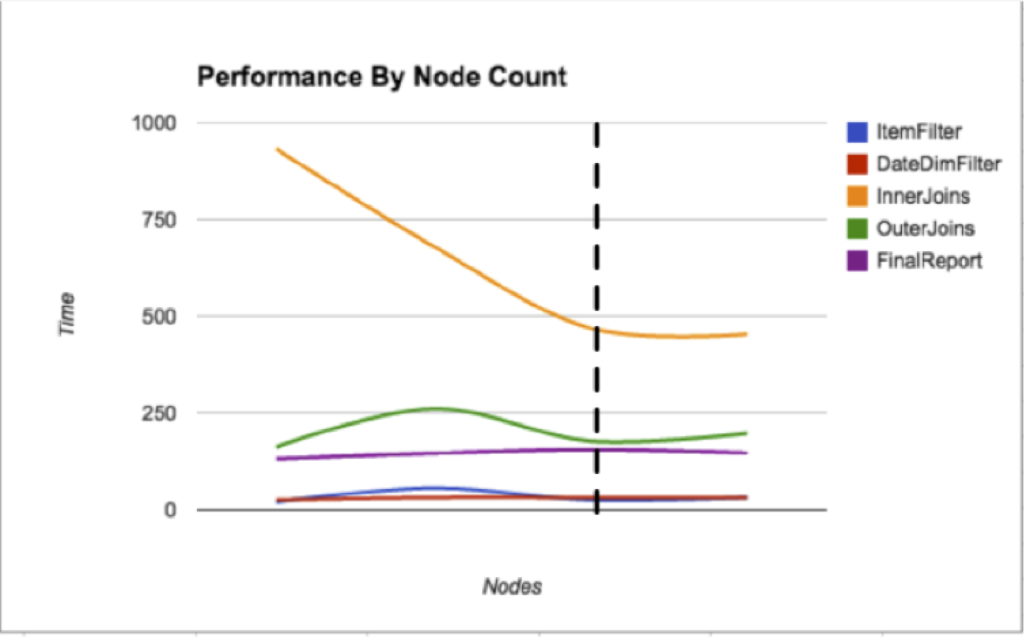
So we’ve discovered a point (the dotted line) where adding more hardware won’t help our application execute faster. InnerJoins (orange line), the most time-consuming stage of the app, initially enjoys a performance boost from additional nodes, but the improvement plateaus.
After the plateau is reached, if the business needs the app to run faster, the development team will have to improve the code for InnerJoins. That could mean taking advantage of business logic and data patterns to make the app more parallel than the naive approach (for example, instead of working on the entire country at once, we could split InnerJoins into parallel components that each handle a zip code). Or, it could mean performing code-level optimizations, like filtering out unused data before InnerJoins runs rather than relying on FinalReport to do that.
Of course, before we expend development effort on InnerJoins, we want to make sure our overall app performance will benefit; we can’t always translate speed gains in one component to overall app performance because components can run in parallel. Driven shows us whether InnerJoins’s longer execution time happens in parallel with other components or whether it’s a bottleneck:
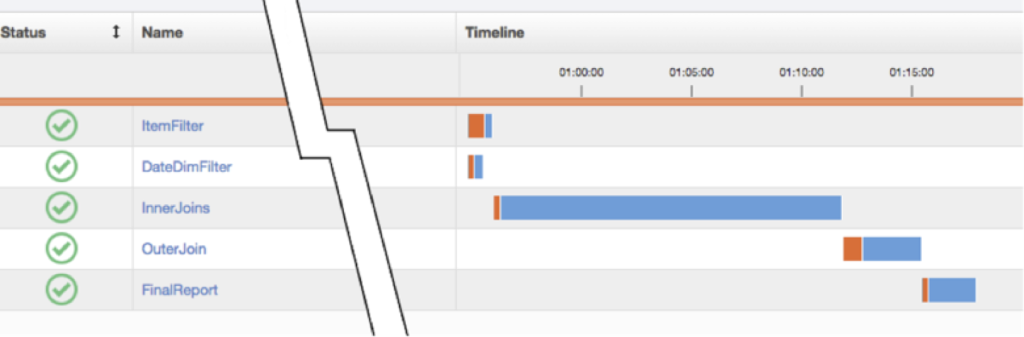
As we noted earlier, InnerJoins is the first of three serial steps, so its execution time directly bottlenecks the whole application. Driven makes it easy to see this, as well as that most of the application’s execution time is spent on InnerJoins.
If we optimize InnerJoins, we should probably only work on improving it until its execution time falls below that of the next-slowest step, OuterJoin. Once we’ve reached that point, it will likely be more efficient to improve OuterJoin. We also know that focusing on DateDimFilter, ItemFilter or FinalReport is not likely to be the best use of developer or operations effort, for three reasons: (1) We saw in the first graph that those steps don’t clearly benefit from more hardware; (2) those steps comprise only a small percentage of the application’s total execution time; and (3) some of those components already run in parallel.
Driven: Powering Dev and Ops Collaboration on Hadoop
In conclusion, Driven gives us a clearer sense of how the application will behave if more hardware is added. After that, further optimizations have to come from more efficient code. Driven can also be used to investigate what kind of code optimizations will be most effective, and I’ll tackle that topic in a future post.
* * *
Ready to give it a shot? Instantly view your Hadoop Apps Online with Driven. Try Now!
About Joe Posner
 Joe Posner is a Senior Software Engineer at Concurrent Inc., where he develops tools for Big Data systems. His background as a software engineer runs the gamut from small startups to Fortune 500 companies and from distributed data systems to traditional databases.
Joe Posner is a Senior Software Engineer at Concurrent Inc., where he develops tools for Big Data systems. His background as a software engineer runs the gamut from small startups to Fortune 500 companies and from distributed data systems to traditional databases.